
В сегодняшней статье мы поговорим про движок полнотекстового поиска и аналитики Elasticsearch. Программа очень быстро развивается, соответственно, увеличивается круг её применения. Изначально Elasticsearch использовался для поиска на сайтах, но сейчас он развился в полноценную базу данных и может применяться для аналитической обработки больших массивов данных, анализа логов серверов и многих других задач.
Тем не менее на русском языке не так много хороших инструкций, описывающих работу этой платформы. Дальше мы рассмотрим, как установить Elasticsearch, а также познакомимся с основами создания и использования индексов, управлением данными и группировкой. В общем, расскажу обо всём, что я узнал об этой программе за последние несколько недель работы с ней.
Содержание статьи
- Системные требования Elasticsearch
- Установка Elasticsearch в Ubuntu
- Настройка Elasticsearch
- Использование Elasticsearch
- Выводы
Системные требования Elasticsearch
Во-первых, надо обратить внимание на системные требования. В официальной документации заявлено, что программа будет идеально работать на машине с 64 Гб оперативной памяти, а минимальный объём - 8 Гб. И это понятно, потому что платформа работает на Java. Но это для производственных масштабов.
От себя же могу сказать, что с обработкой 1 млрд строк данных Elasticsearch неплохо справляется и на машине с 2 Гб, не так быстро как хотелось бы, но там, где MySQL задумывалась на несколько минут, Elasticsearch выдаёт результат почти мгновенно. Однако для машин с небольшим количеством ОЗУ нужна дополнительная настройка.
К процессору особых требований нет, что касается дисков, то разработчики советуют использовать SSD, так как они позволят быстрее выполнять операции индексирования и чтения данных с диска.
Установка Elasticsearch в Ubuntu
Elasticsearch - это оболочка для библиотеки Lucene, которая написана на Java. А поэтому для установки платформы вам необходимо установить Java. Разработчики рекомендуют использовать Java 8 версии 1.8.0_131 или выше. Мы будем рассматривать установку на примере Ubuntu. Установим OpenJDK:
sudo apt install openjdk-8-jre
Смотрим версию Java:
java -version
Если у вас уже установлена другая версия, то этот шаг можно пропустить. Затем добавляем репозиторий Elasticsearch:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
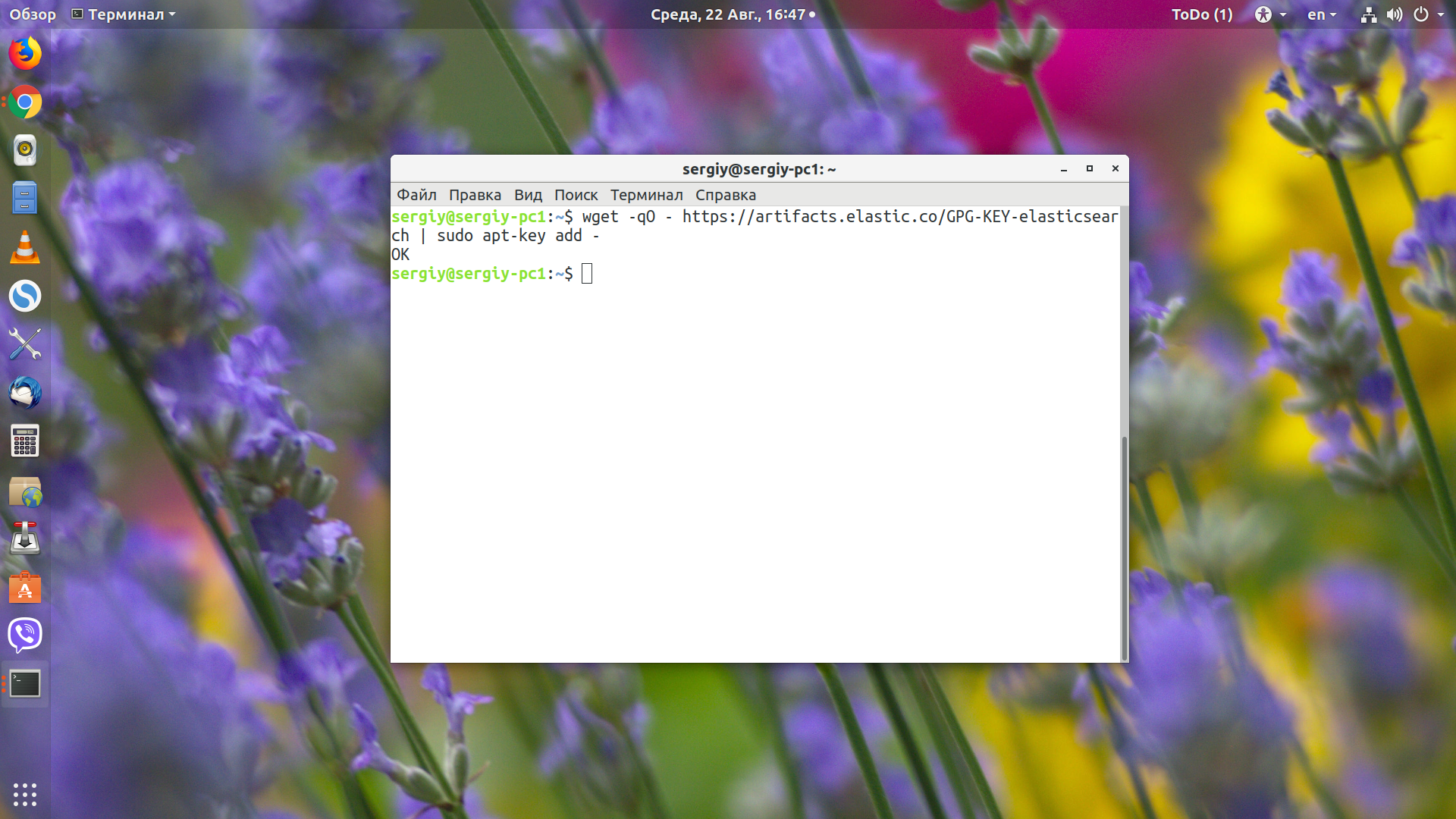
sudo apt-get install apt-transport-https
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
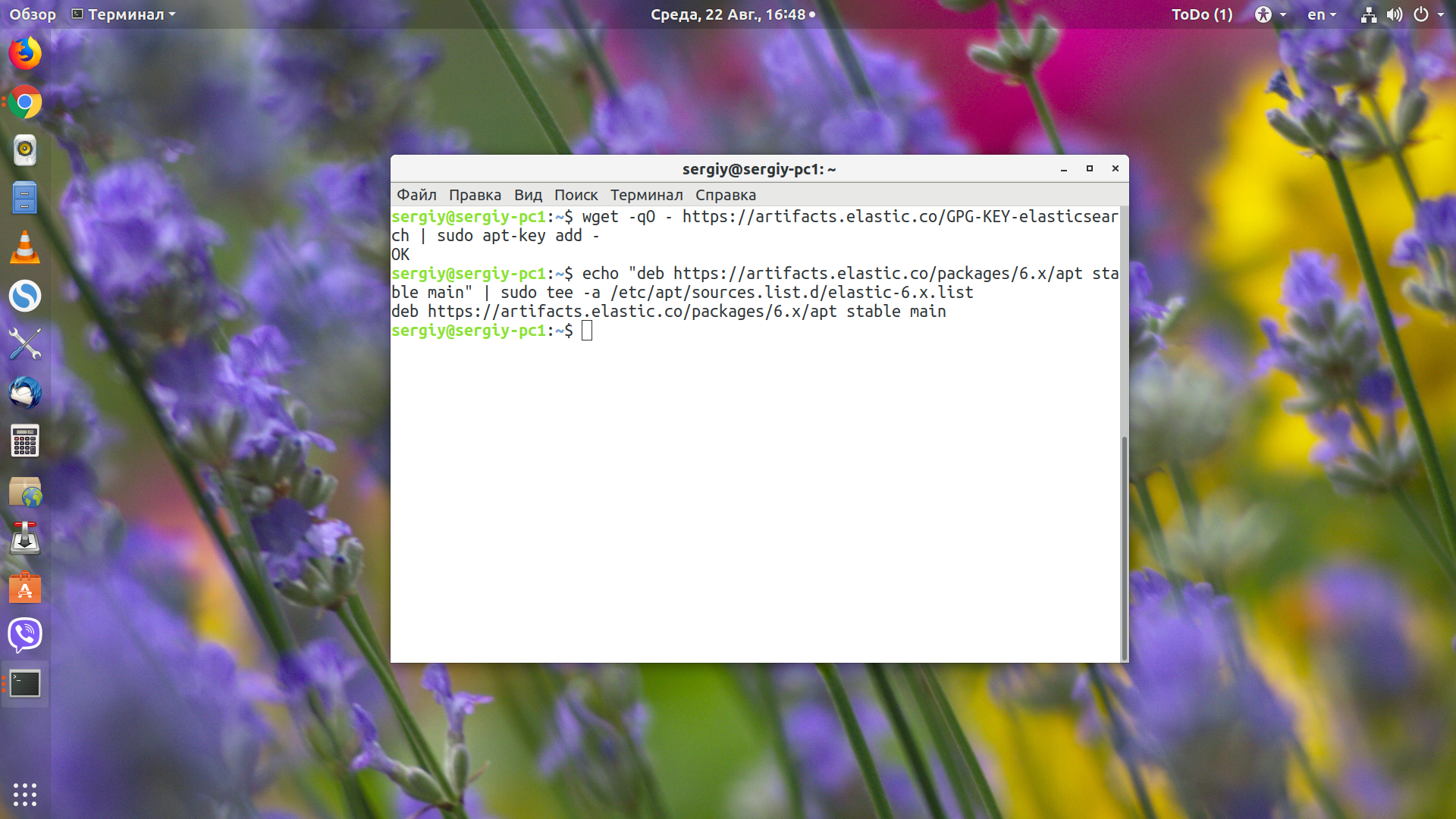
И установка ElasticSearch:
sudo apt-get update && sudo apt-get install elasticsearch
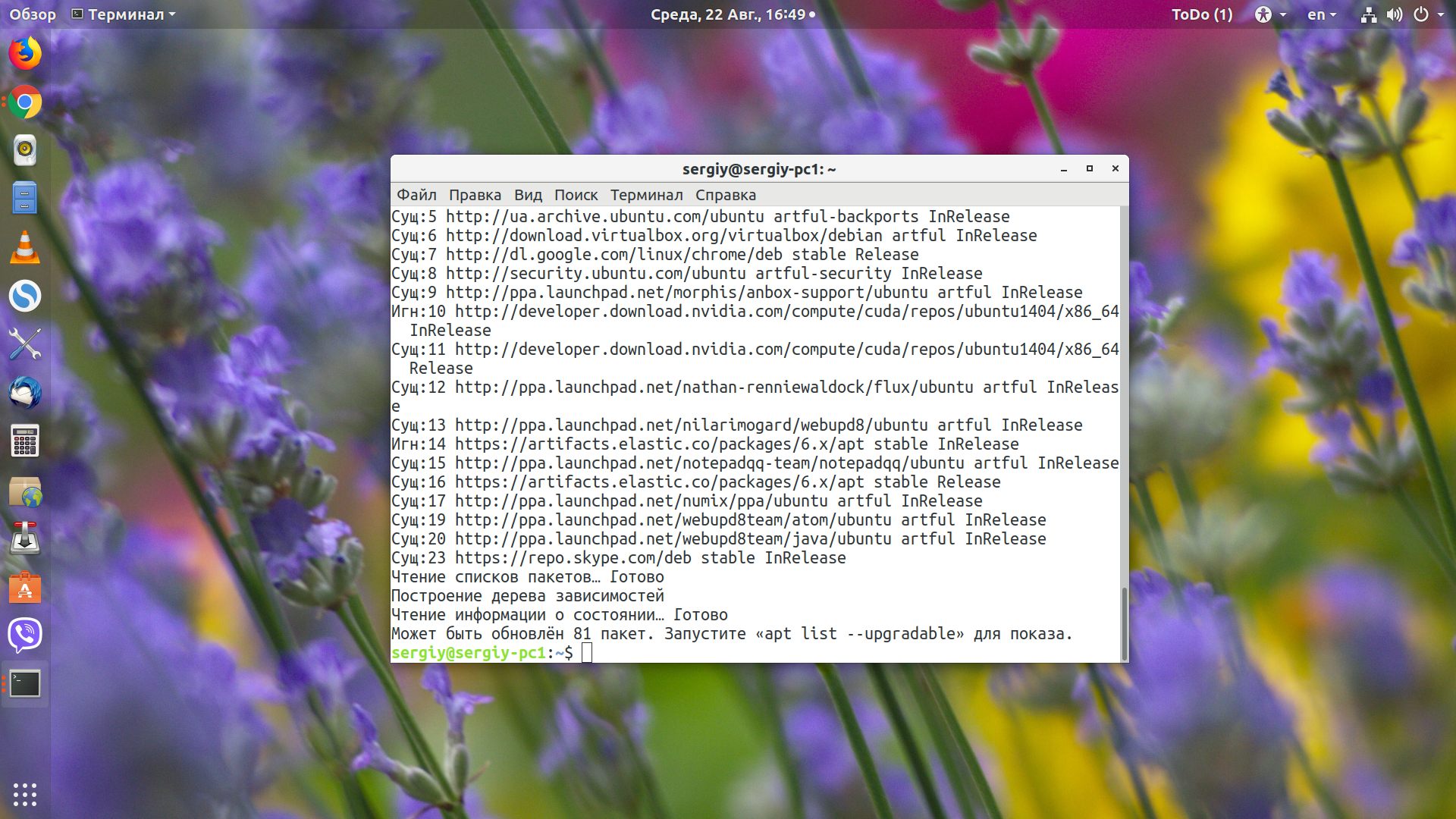
В rpm дистрибутивах достаточно просто скачать и установить rpm пакет.
Настройка Elasticsearch
После завершения установки Elasticsearch нужно запустить и добавить в автозагрузку его службу, для этого выполните:
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch
Для машин с небольшим количеством ОЗУ нужно ограничить количество памяти, потребляемой программой. Для этого откройте файл /etc/elasticsearch/jvm.options и измените значение опций -Xms и -Xmx на то количество памяти, которое вы хотите, чтобы программа использовала. Например:

Теперь нужно перезапустить сервис:
sudo systemctl restart elasticsearch
Использование Elasticsearch
1. Просмотр версии Elasticsearch
Для общения с Elasticsearch используется RESTful API или, если говорить простым языком, обыкновенные HTTP-запросы. И работать с ним мы можем прямо из браузера. Но делать этого не будем, а будем использовать Linux-утилиту curl. Для просмотра информации о сервисе достаточно обратиться по адресу localhost:9200:
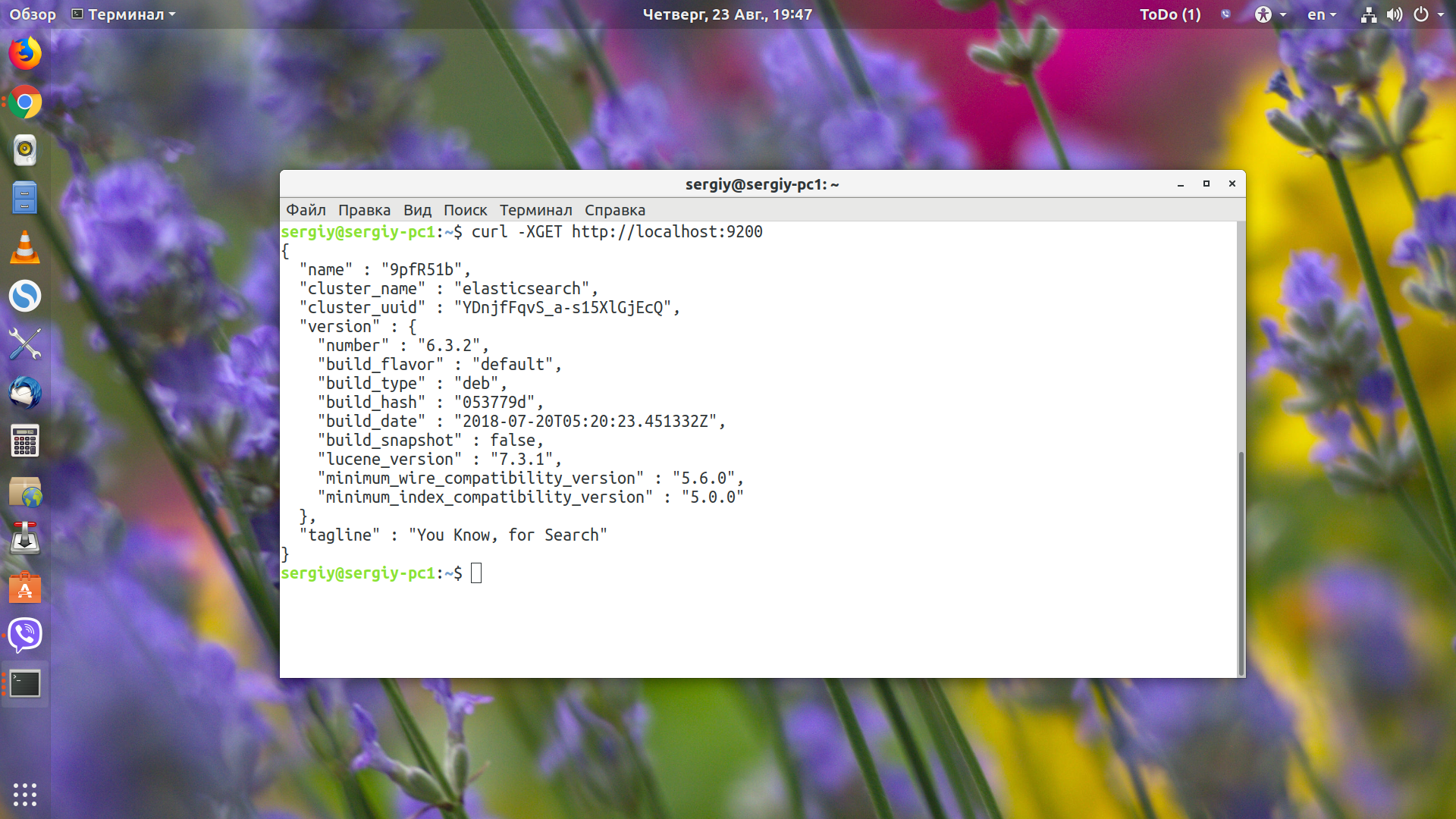
curl -XGET http://localhost:9200
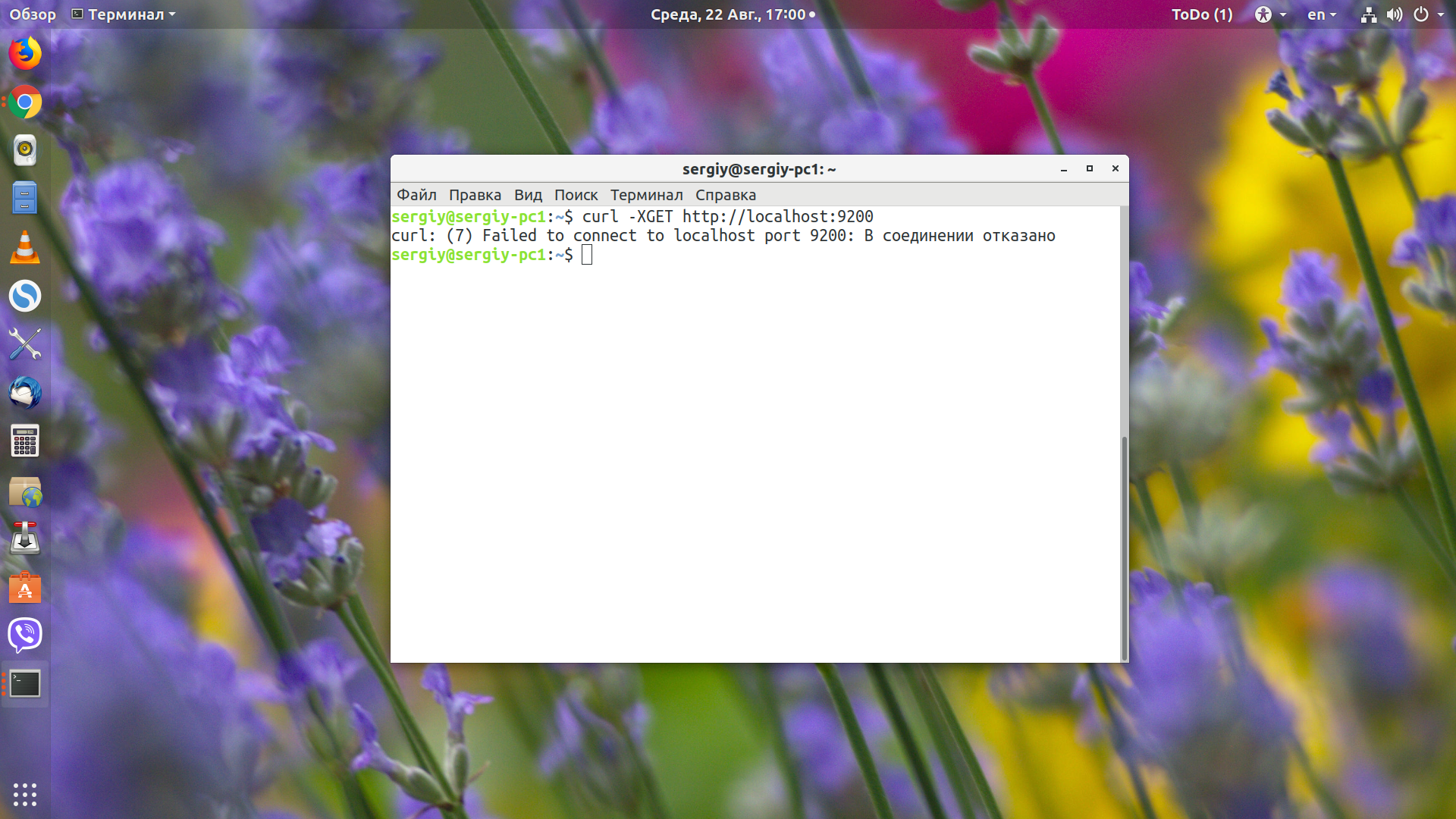
Опция -X задаёт протокол, который мы используем. В этой статье мы используем не только GET, но и POST, PUT, DELETE и другие. Если вы только что перезапустили сервис и получаете ошибку "http://localhost:9200 - conection refused", то ничего страшного - система загружается, надо подождать несколько минут.
Если будете пытаться ей помешать, можете потерять уже проиндексированные данные. Просто убедитесь, что сервис уже запущен (active) командой:
sudo systemctl status elasticsearch
Когда платформа загрузиться, вы получите такой ответ:
2. Список индексов Elasticsearch
Точно так же, как MySQL может иметь несколько баз данных, Elastic может иметь несколько индексов. У каждого из них может быть несколько отдельных таблиц (type), каждая из которых будет содержать документы (doc), которые можно сравнить с записями в таблице MySQL.
Чтобы посмотреть текущий список индексов, используйте команду _cat:
curl 'localhost:9200/_cat/indices?v&pretty'
Общий синтаксис использования глобальных команд такой:
curl 'localhost:9200/_команда/имя?параметр1&параметр2'
- _команда - обычно начинается с подчеркивания и указывает основное действие, которое надо сделать;
- имя - параметр команды, указывает, над чем нужно выполнить действие, или уточняет, что надо делать;
- параметр1 - дополнительные параметры, которые влияют на отображение, форматирование, точность вывода и так далее;
Например, команда _cat также может отобразить общее "здоровье" индексов (health) или список активных узлов (nodes). Параметр v включает более подробный вывод, а pretty сообщает, что надо форматировать вывод в формате json (чтобы было красиво).
3. Индексация данных
Вообще, вам не обязательно создавать индекс. Вы можете просто начать записывать в него данные, как будто бы он и таблица уже существует. Программа создаст всё автоматически. Для записи данных используется команда _index. Вот только однострочной команды curl нам будет уже недостаточно, надо добавить ещ сами данные в формате json, поэтому создадим небольшой скрипт:
vi elastic_index.sh
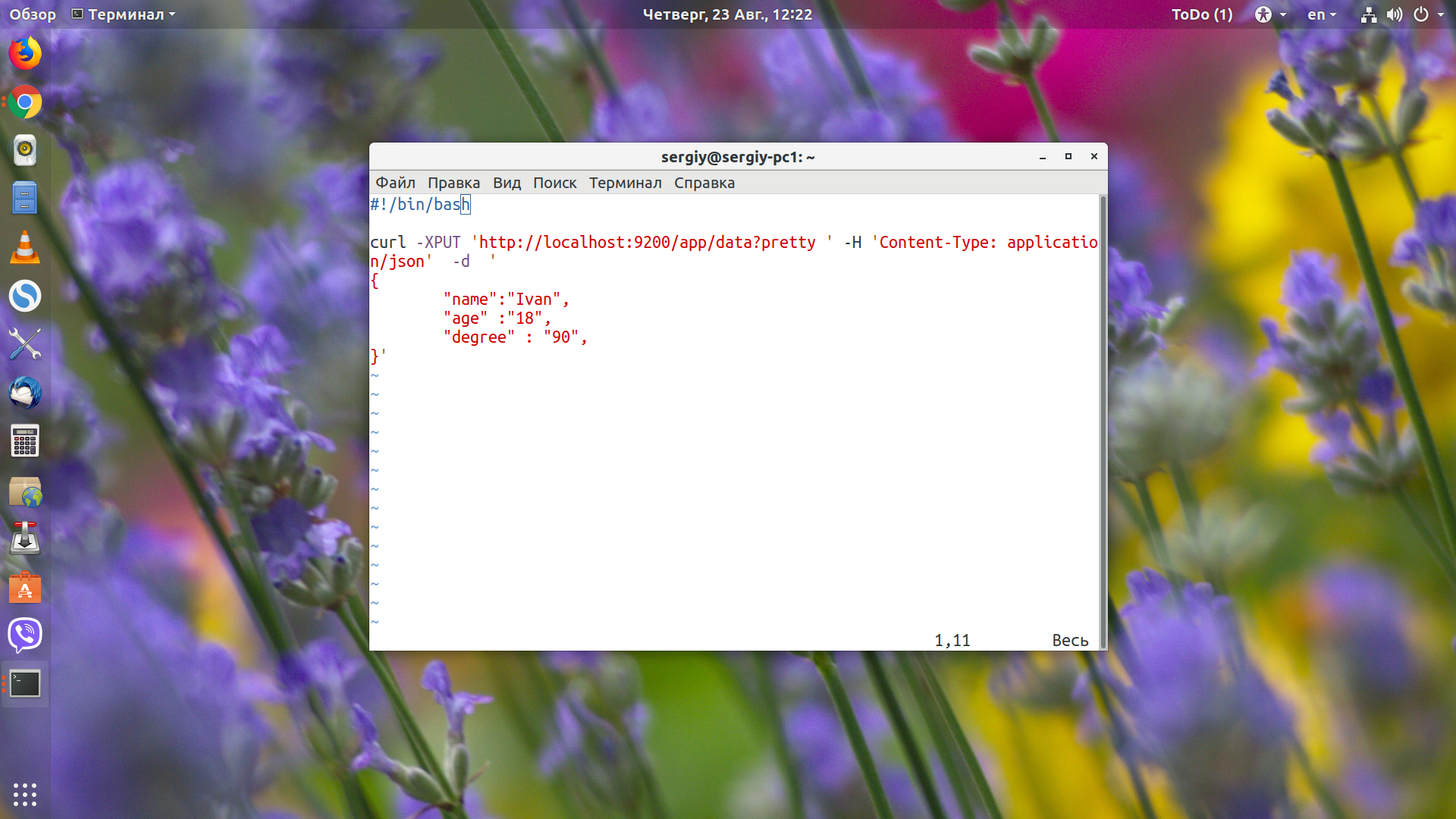
Здесь я записываю данные: индекс app, таблицу data. Так как они не существуют, система их создаст. Как видите, сами данные нам нужно передать в формате json. Передаём заголовок с помощью опции -H, будем отсылать json, а потом с помощью -d передаём сами данные. Данные представляют из себя три поля:
- name - имя;
- age - возраст;
- degree - оценка.
Нам следует ещё остановиться на синтаксисе формата JSON:
{
"имя_поля" : "значение_поля",
"имя_поля1": "значение_поля",
"имя_поля2": {
"имя_поля3": "значение поля",
"имя_поля4": ["значение1", "значение2"]
}
}
Если вы знакомы с JavaScript, то уже знаете этот формат. Если нет, то ничего страшного, сейчас разберёмся. Данные представляются в виде пар имя: значение. И имя поля, и его значение нужно брать в кавычки и разделять их двоеточием. Каждая пара отделяется от следующей с помощью запятой. Но если пар больше нет, то кома не ставится. Причём каждое поле может иметь в качестве значения либо текст, либо ещё один набор полей, заключённый в фигурные скобки {}. Если нужно перечислить два элемента без названия поля, надо использовать не фигурные скобки, а квадратные [] (массив), как в поле4. Для удобства форматирования используйте пробелы, табуляции Elasticsearch не понимает.
Теперь сохраняем скрипт и запускаем:
sh elastic_index.sh
Если всё прошло успешно, то вы увидите такое сообщение:
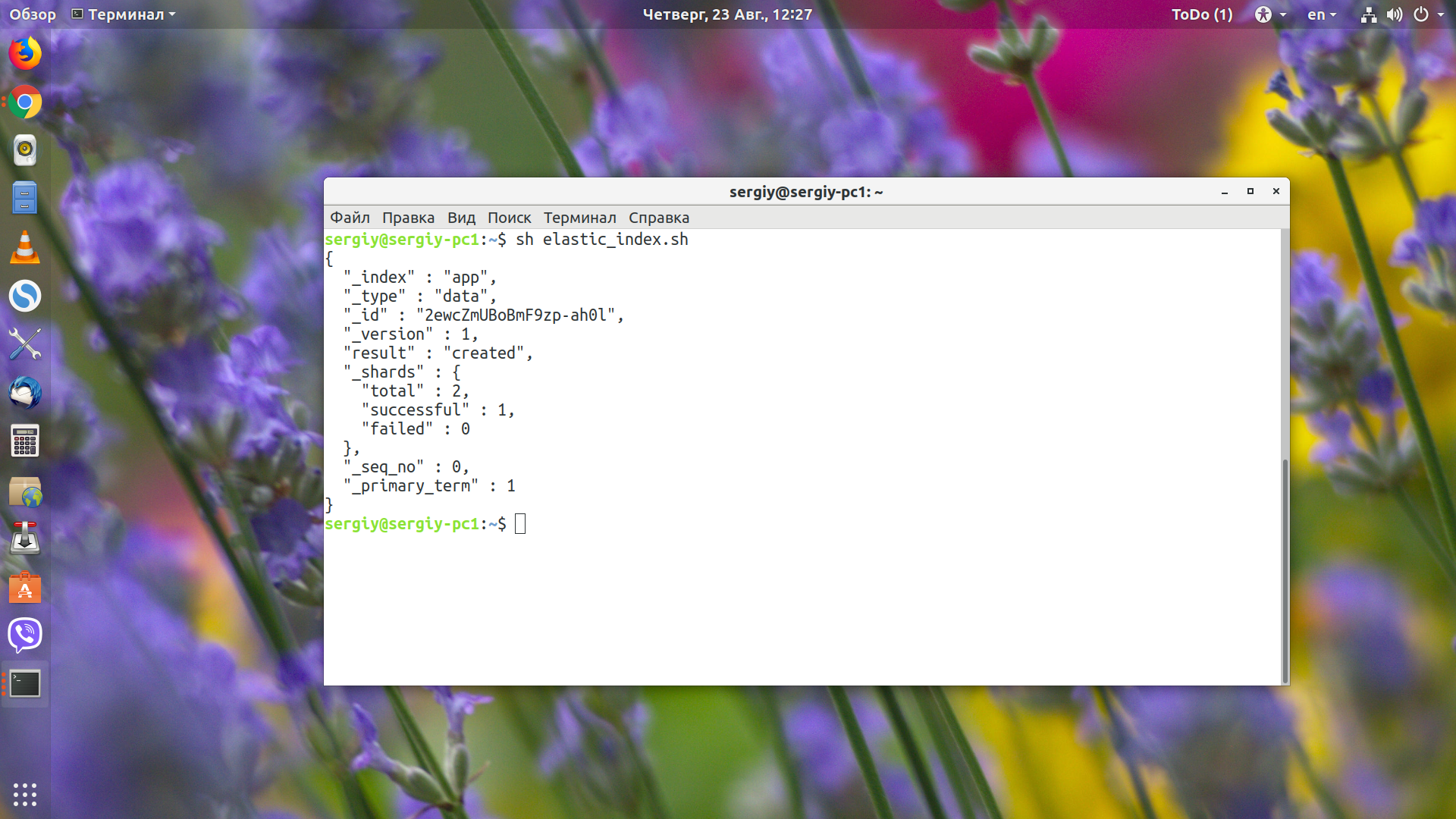
Это значит, что документ добавлен в индекс. Теперь вы можете снова посмотреть список индексов.
4. Информация об индексе
Мы знаем список созданных индексов, но как посмотреть список типов (таблиц) в индексе и как узнать, какие и каких типов поля созданы в индексе? Для этого можно использовать команду _mapping. Но перед тем, как мы перейдём к ней, надо вернуться к синтаксису. Команды могут применяться как к глобально, так и для отдельного индекса или для отдельного типа. Синтаксис будет выглядеть так:
curl 'localhost:9200/индекс/тип/_команда/имя?параметр1&параметр2'
Чтобы посмотреть все индексы и их поля, можно применить команду глобально:
curl 'localhost:9200/_mapping?pretty'
Или только для индекса app:
curl 'localhost:9200/app/_mapping?pretty'
Только для типа data индекса app:
curl 'localhost:9200/app/data/_mapping?pretty'
В результате программа вернула нам ответ, в котором показан индекс app, в нём есть тип data, а дальше в поле properties перечислены все поля, которые есть в этом типе: age, degree и name. Каждое поле имеет свои параметры.
5. Информация о поле и мультиполя
Каждое поле описывается таким списком параметров:
"age" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
Параметр type - указывает тип поля. В данном случае программа решила, что это текст, хотя это число. Дальше интереснее, у нас есть ещё параметр fields. Он задаёт так называемые подполя или мультиполя. Поскольку Elasticsearch - это инструмент поиска текста, то для обработки текста используются анализаторы, нормализаторы и токенизаторы, которые могут приводить слова к корневой форме, переводить текст в нижний регистр, разбивать текст на отдельные слова или фразы. Вс` это нужно для поиска и по умолчанию применяется к каждому текстовому полю.
Но если вам нужно просто проверить точное вхождение фразы без её изменений, то с проанализированным таким образом полем у вас ничего не получиться. Поэтому разработчики придумали мультиполя. Они содержат те же данные, что и основное поле, но к ним можно применять другие анализаторы, или вообще их не применять. В нашем примере видно, что система автоматически создала подполе типа keyword, которое содержит неизмененный вариант текста.
Таким образом, если вы захотите проверить точное вхождение, то нужно обращаться именно к полю age.keyword а не к age. Или же отключить анализатор для age. Анализаторы выходят за рамки этой статьи, но именно эта информация нам ещё понадобится дальше.
6. Удаление индекса
Чтобы удалить индекс, достаточно использовать вместо GET протокол DELTE и передать имя индекса:
curl -XDELETE 'http://localhost:9200/app?pretty'
Теперь индекс удалён. Создадим ещё один такой же вручную.
7. Ручное создание индекса
Программа создала для цифр текстовые поля, к ним применяется анализ текста и индексация, а это потребляет дополнительные ресурсы и память. Поэтому лучше создавать индекс вручную и настраивать такие поля, какие нам надо. Первых два поля сделаем int без подполей, а третье оставим как есть. Запрос будет выглядеть так:
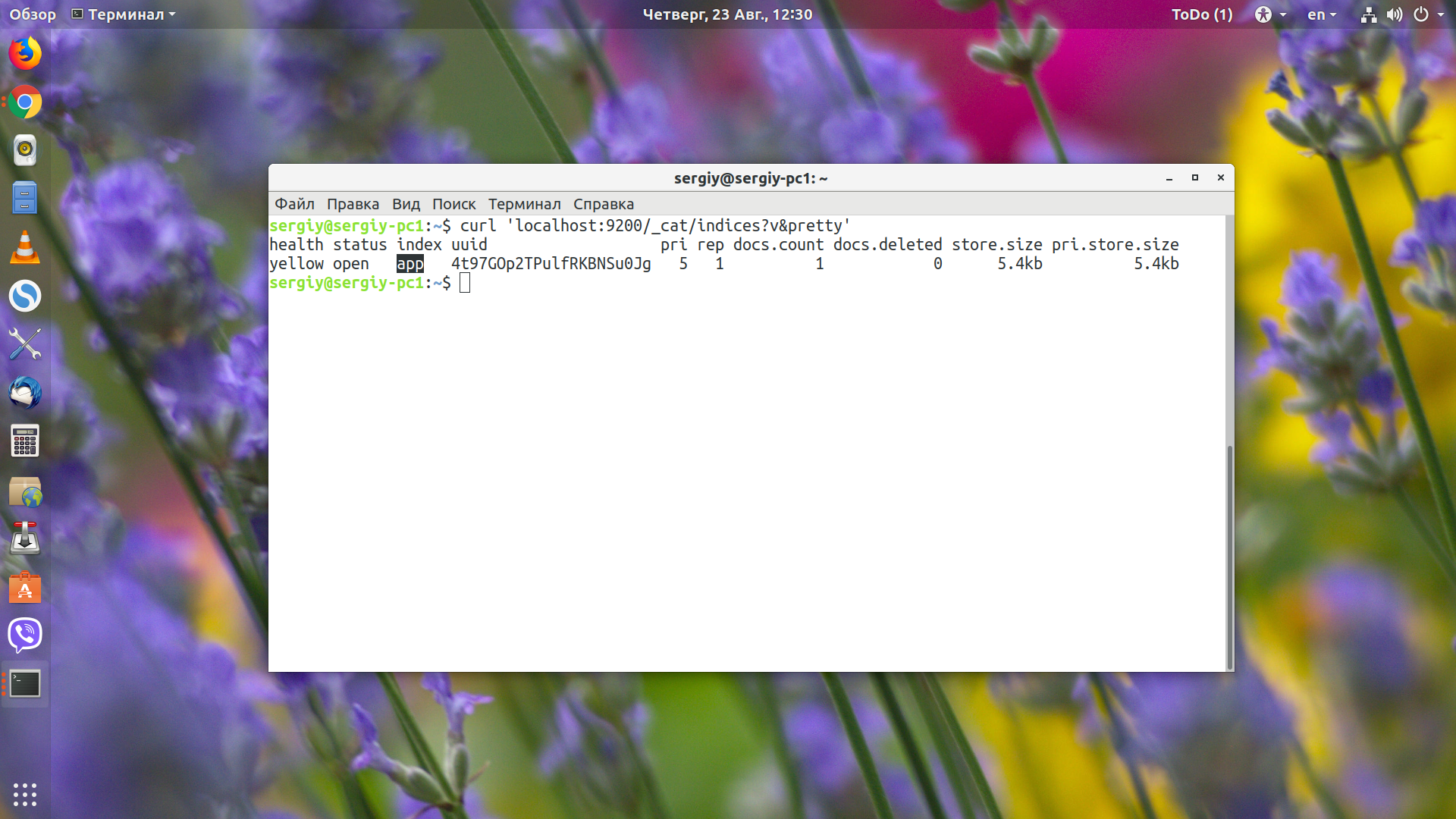
vi elastic_createindex.sh

Как видите, здесь используется тот же синтаксис, который программа возвращает при вызове команды _mapping. Осталось запустить скрипт, чтобы создать индекс:
sh elastic_createindex.sh
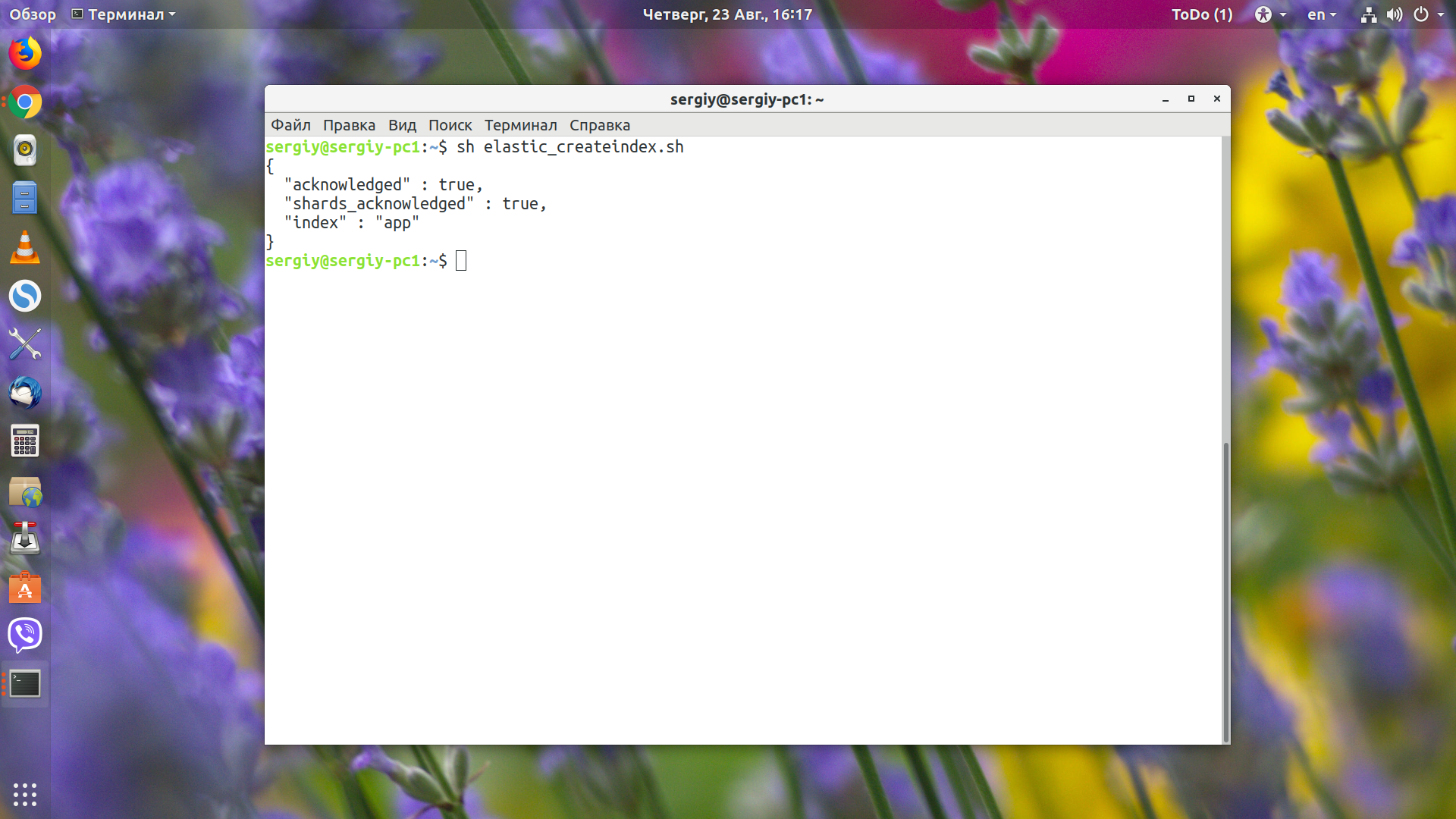
Чтобы всё прошло нормально, необходимо удалить индекс, который был создан автоматически, поэтому предыдущий пункт расположен там не зря. Вы можете менять mappings для существующего индекса, но в большинстве случаев для применения изменений к существующим данным индекс надо переиндексировать. Например, если вы добавляете новое мультиполе, то в нём можно будет работать только с новыми данными. Старые данные, которые были там до добавления, при поиске будут недоступны.
5. Массовая индексация данных
Дальше я хотел бы поговорить о поиске, условиях и фильтрации, но чтобы почувствовать полную мощьность всех этих инструментов нам, нужен полноценный индекс. В качестве индекса мы будем использовать один из демонстрационных индексов, в который разложены пьесы Шекспира. Для загрузки индекса наберите:
wget https://download.elastic.co/demos/kibana/gettingstarted/shakespeare_6.0.json
В файле находятся данные в формате json, которые надо проиндексировать. Это можно сделать с помощью команды _bluck:
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/shakespeare/doc/_bulk?pretty' --data-binary @shakespeare_6.0.json
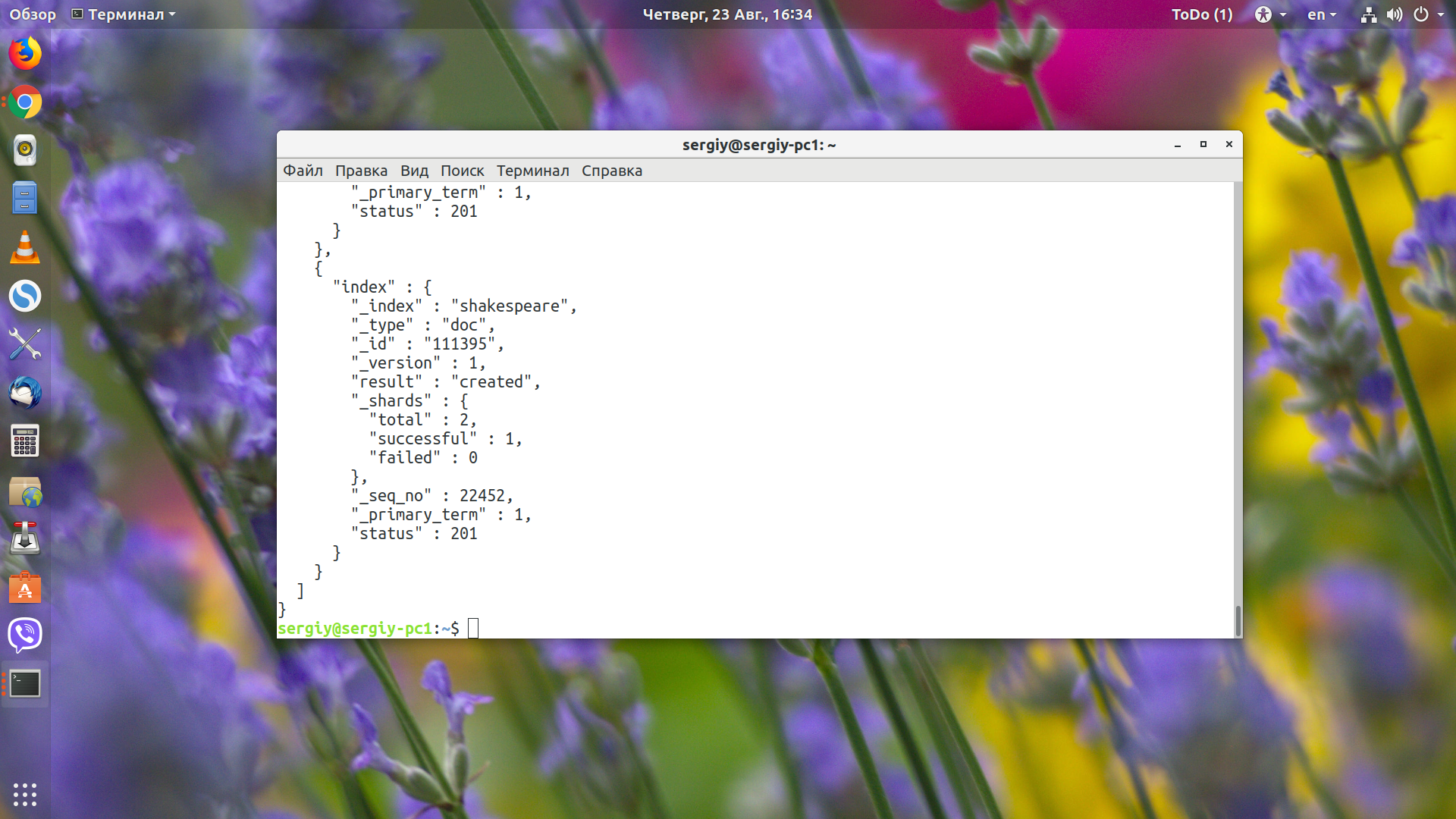
Индексация работает так же, как и при ручном добавлении данных, но благодаря оптимизации команды _bluck, выдаёт результат намного быстрее.
6. Поиск по индексу
Для поиска или, другими словами, выборки данных в Elasticsearch используется команда _search. Если вызвать команду без параметров, то будут обрабатываться все документы. Но выведены будут только первые 10, потому что это ограничение по умолчанию:
curl -XGET 'http://localhost:9200/shakespeare/doc/_search?pretty'
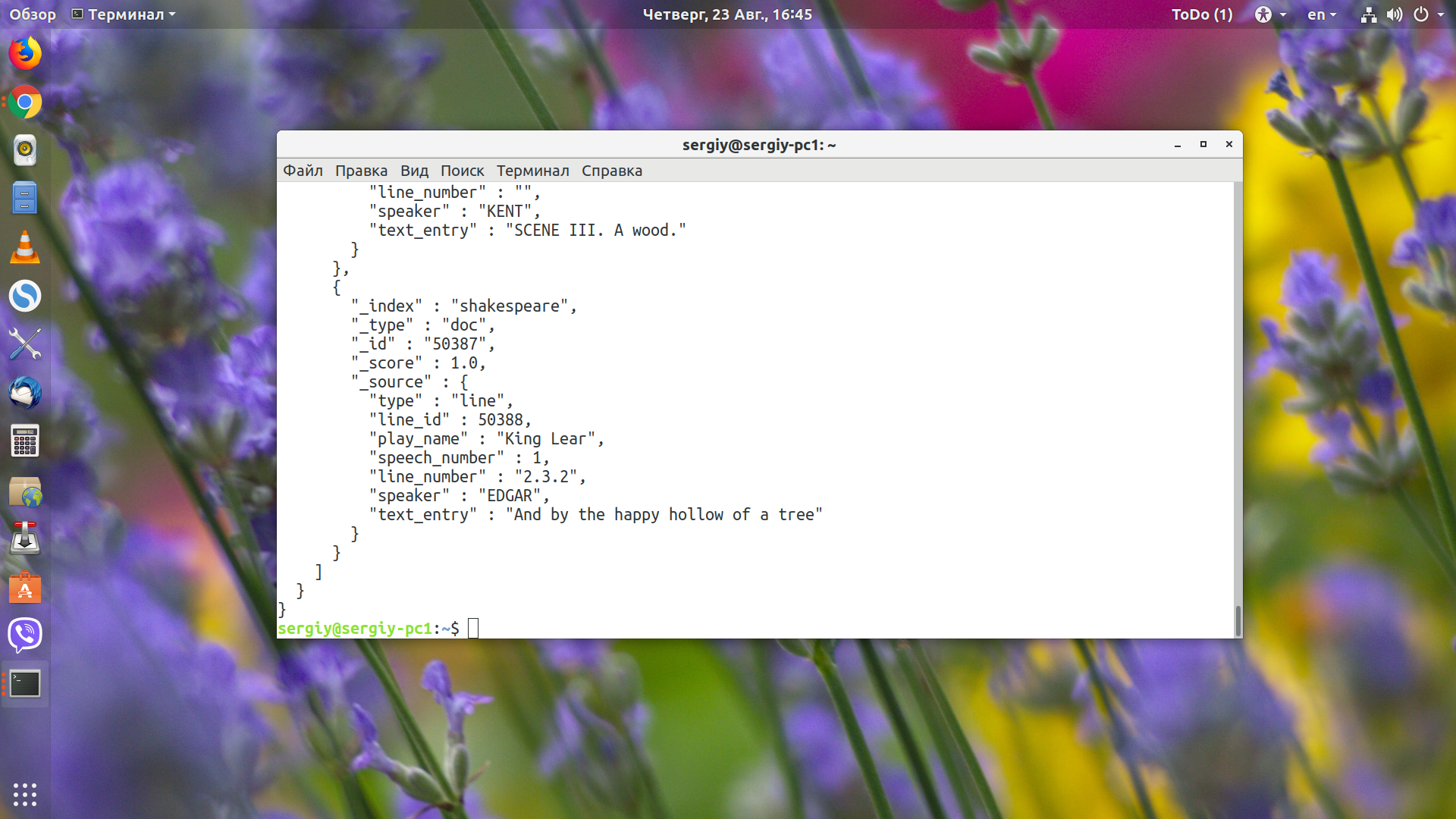
Здесь мы выбрали первые десять документов из индекса shakespeare и таблицы doc. Чтобы выбрать больше, передайте параметр size со значением, например 10000:
curl -XGET 'http://localhost:9200/shakespeare/doc/_search?size=10000&pretty'
Самый простой пример поиска - передать поисковый запрос в параметре q. При этом поиск Elasticsearch будет выполняться во всех полях индекса. Например, найдём все, что касается Эдгара (EDGAR):
curl -XGET 'http://localhost:9200/shakespeare/doc/_search?q=EDGAR&pretty '
Но как вы понимаете, всё это очень не точно и чаще всего надо искать по определённым полям. В Elasticsearch существует несколько типов поиска. Основные из них:
- term - точное совпадение искомой строки со строкой в индексе или термом;
- match - все слова должны входить в строку, в любом порядке;
- match_phrase - вся фраза должна входить в строку;
- query_string - все слова входят в строку в любом порядке, можно искать по нескольким полям, используя регулярные выражения;
Синтаксис term такой:
"query" {
"term" {
"имя_поля": "что искать"
}
}
Например, найдем записи, где говорит Эдгар с помощью term:
vi elastic_searchterm.sh
sh elastic_searchterm.sh

Мы нашли десять реплик, которые должен сказать Эдгар. Дальше испытаем неточный поиск с помощью match. Синтаксис такой же, поэтому я его приводить не буду. Найдём предложения, которые содержат слова of love:
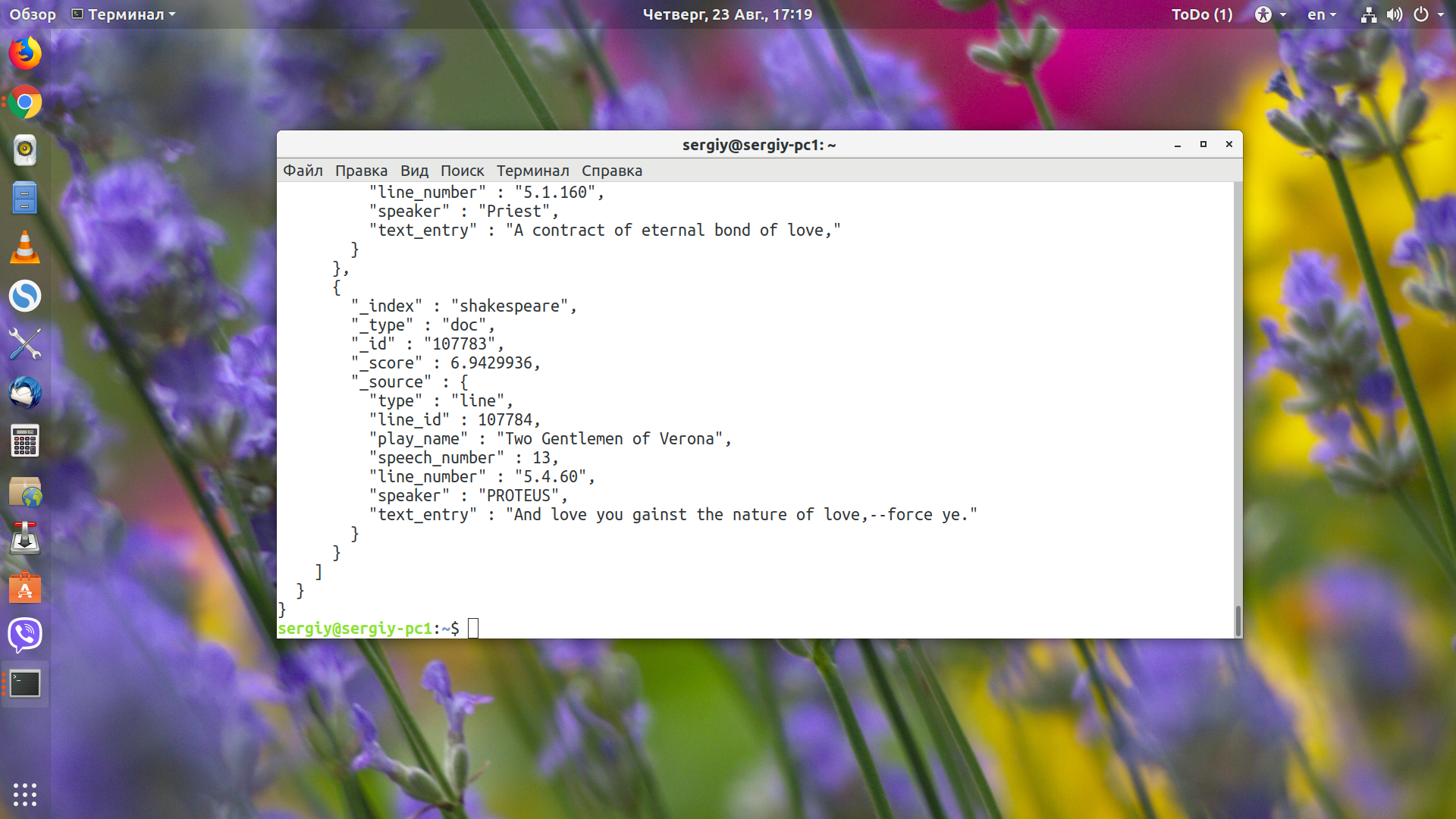
С query_string и match_phrase разберётесь сами, если будет нужно.
8. Операторы AND и OR для поиска
Если вы хотите сделать выборку по нескольким полям и использовать для этого операторы AND и OR, то вам понадобится конструкция bool. Синтаксис её такой:
"query": {
"bool" : {
"must" : [
{"поле1" : "условие"},
{"поле2" : "условие"},
],
"filter": {},
"must_not" : {}
"should" : {}
}
}
Обратите внимание на синтаксис. Поскольку у нас два элемента подряд, мы используем массив []. Но так как дальше нам снова нужно создавать пары ключ:значение, то в массиве открываются фигурные скобки. Конструкция bool объединяет в себе несколько параметров:
- must - все условия должны вернуть true;
- must_not - все условия должны вернуть false;
- should - одно из условий должно вернуть true;
- filter - то же самое что и match, но не влияет на оценку релевантности.
Например, отберём все записи, где Helen говорит про любовь:
vi elastic_searchbool.sh
Как видите, найдено только два результата.
9. Группировка
И последнее, о чём мы сегодня поговорим, - группировка записей в Еlasticsearch и суммирование значений по ним. Это аналог запроса GOUP BY в MySQL. Группировка выполняется с помощью конструкции aggregations или aggs. Синтаксис её такой:
"aggregations" : {
"название" : {
"тип_группировки" : {
параметры
},
дочерние_группировки
}
}
Разберём по порядку:
- название - указываем произвольное название для данных, используется при выводе;
- тип_группировки - функция группировки, которая будет использоваться, например terms, sum, avg, count и так далее;
- параметры - поля, которые будем группировать и другие дополнительные параметры;
- дочерние группировки - в каждую группировку можно вложить ещё одну или несколько других таких же группировок, что делает этот инструмент очень мощным.
Давайте подсчитаем, сколько отдельных реплик для каждого человека. Для этого будем использовать группировку terms:
vi elastic-group.sh
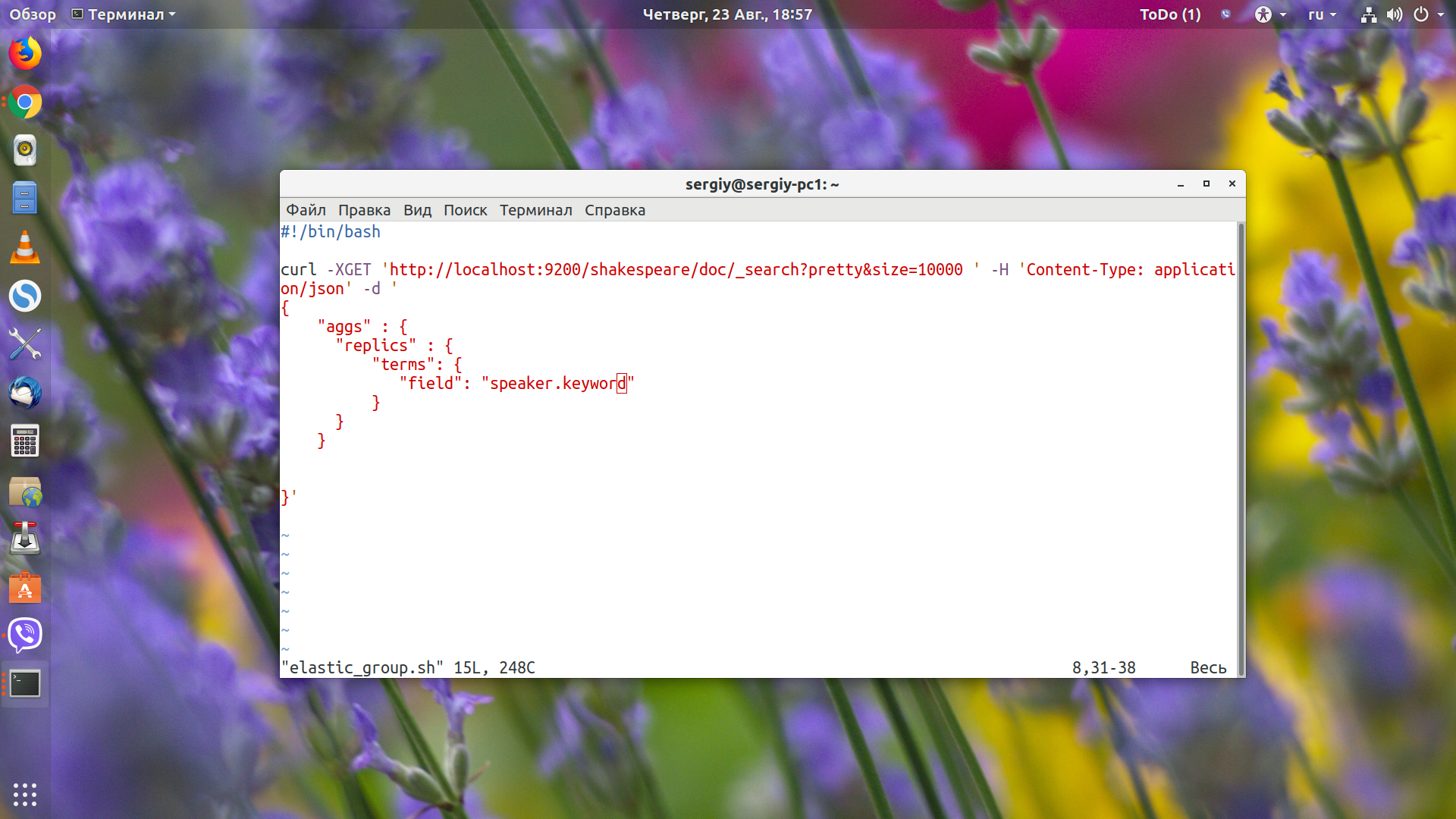
В результате запроса Еlasticsearch получим:
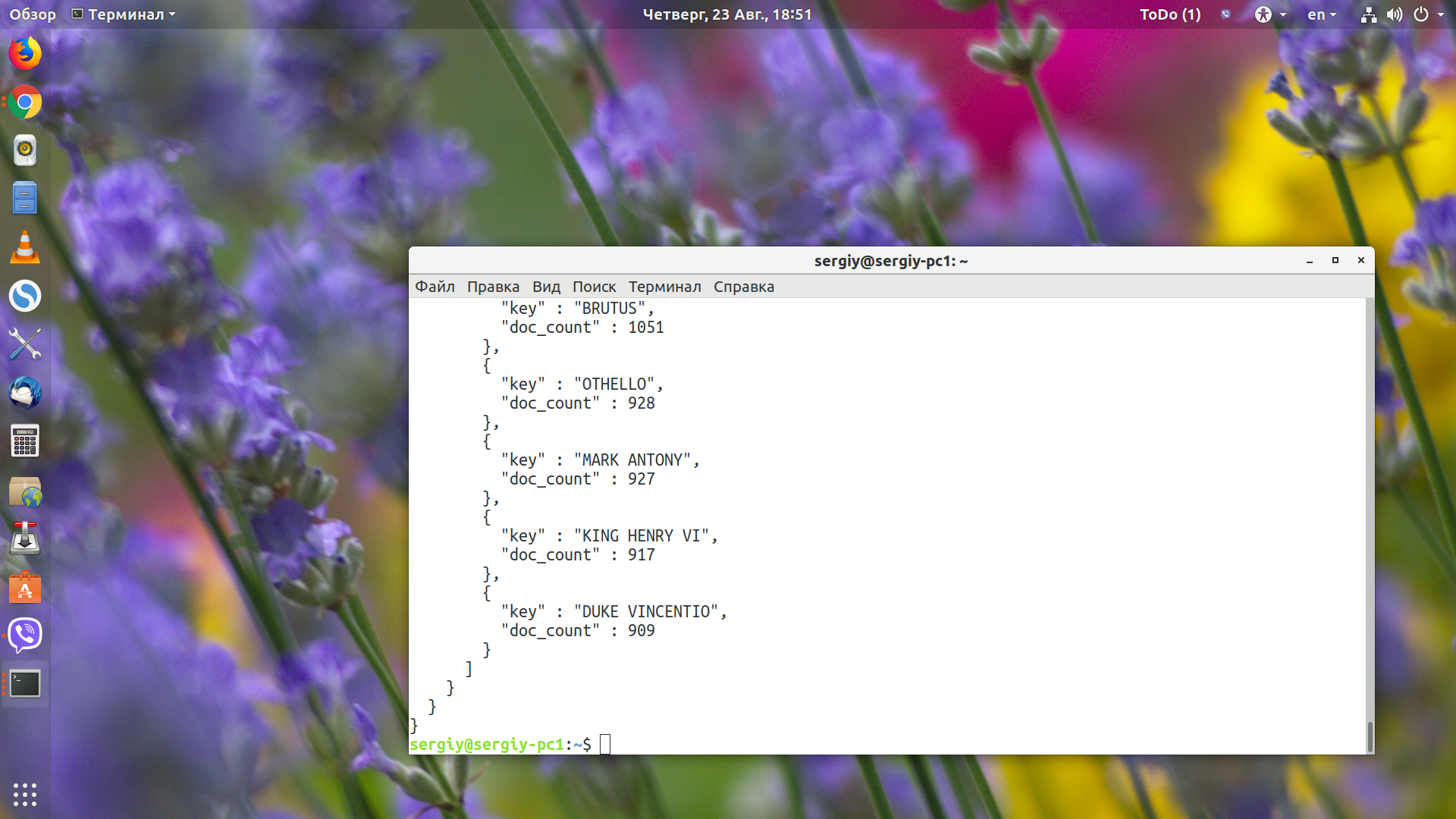
Сначала пойдут все найденные документы, а затем в разделе aggregations мы увидим наши значения. Для каждого имени есть doc_count, в котором содержится количество вхождений этого слова. Чтобы продемонстрировать работу вложенных группировок, давайте найдём сумму и среднее значение поля line_number для каждого участника:
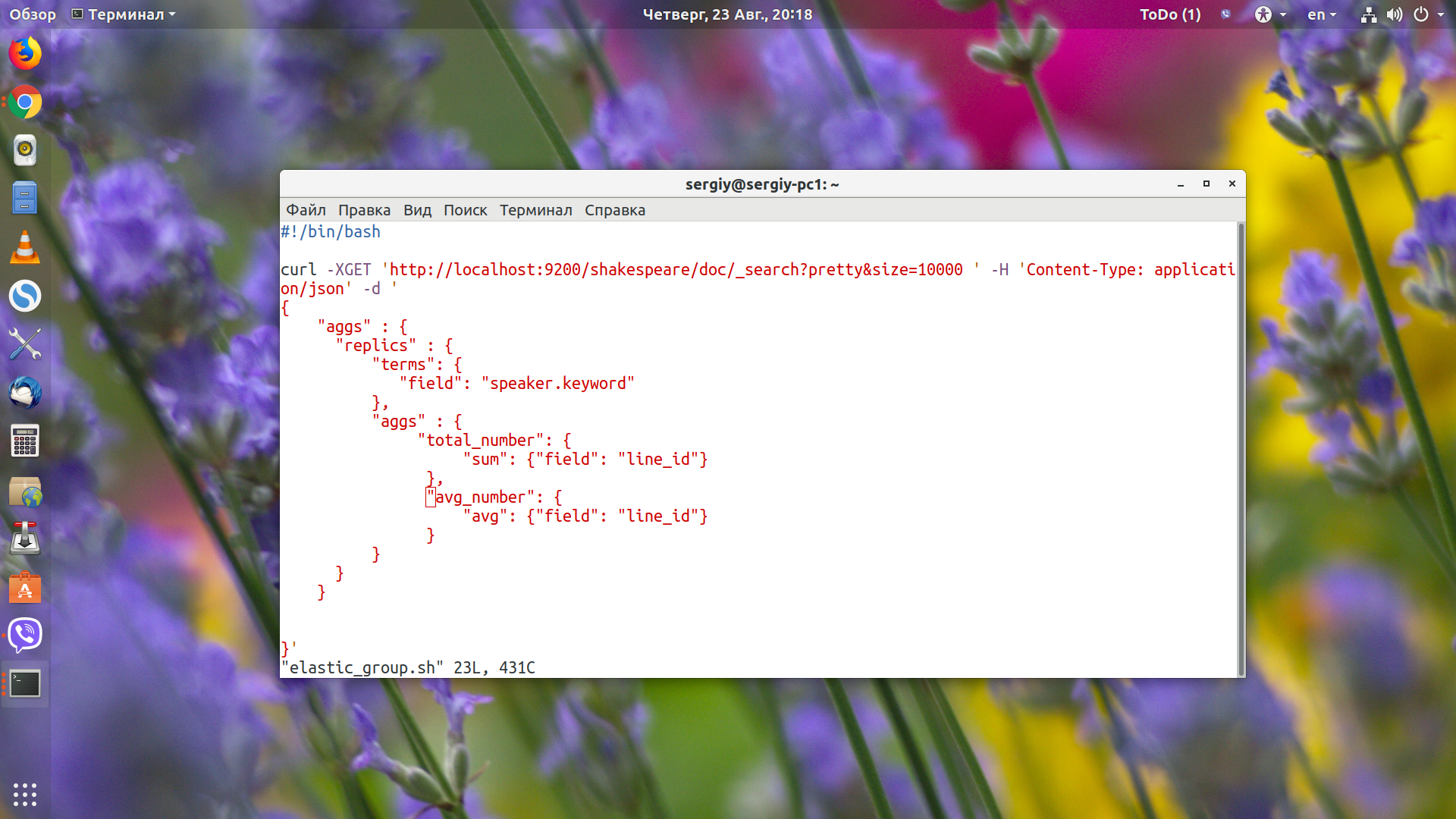
В сумме у нас очень большие числа, поэтому они отображаются в экспоненциальном формате. А вот в среднем значении всё вполне понятно.
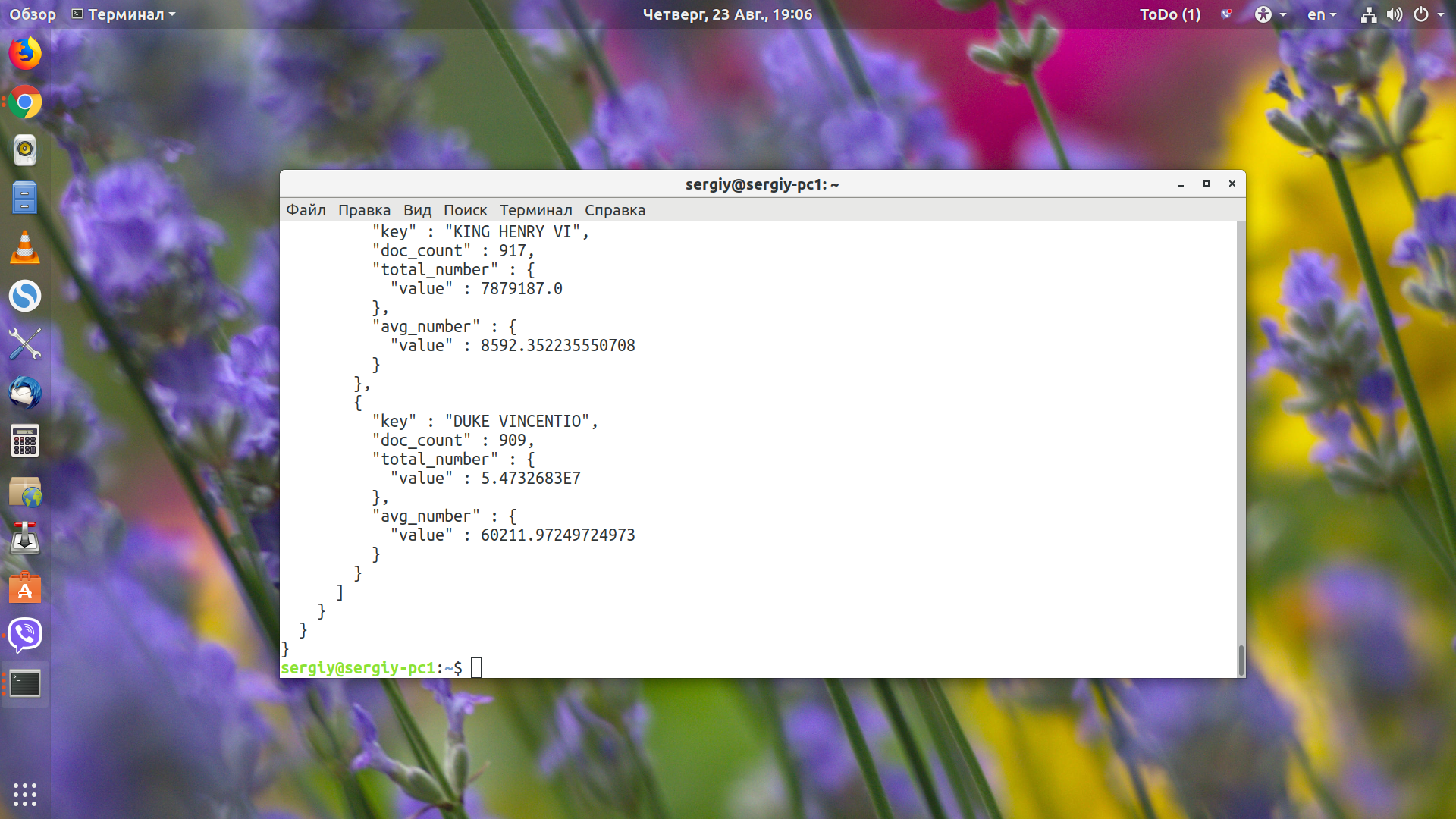
Тут key - имя персонажа, total_number.value - сумма поля, avg_number.value - среднее значение поля.
Выводы
Пожалуй это всё, статья и так очень сильно затянулась. Но и этого материала будет вполне достаточно, чтобы начать использование Elasticsearch в своих проектах. Понятно, что вы не будете там пользоваться curl, у программы есть библиотеки для различных языков программирования, в том числе и для php. Если вы нашили ошибки или неточности в описании работы Еlasticsearch, поправьте меня в комментариях!


 (11 оценок, среднее: 4,55 из 5)
(11 оценок, среднее: 4,55 из 5)
Админ! Низкий поклон тебе! Наконец-то! Наконец-то я дождался этого дня, когда (надеюсь) Лосст перешёл на новый уровень контента. Или, как нынче говорят - годнота подъехала!
Давайте побольше статей для недолбо@бов, да и последние тоже пусть читают и развиваются, прокачивая свои скиллы в Линуксе и мозг в целом. Давно пора заканчивать с этими "Установка Minecraft" и прочие, аналогичные виндузятникам начала 00-х "Как установить и пропатчить фотошоп на виндоус икспи"..
Сайт такой бешеный потенциал в себе несёт. Он же вполне может стать топом сегмента, что в наше время в любой отрасли очень и очень сложно в виду переизбытка и занятости. А здесь - такой старт. И ведь сколько проектов из-за неправильного контента канули в лету - Убунтовод, Пингвинукс и тд. Мне кажется, если Вы писали ерунду ранее в целях СЕО и привлечения ЦА - то сейчас нужно бить именно в уникальность, наращивая уровень знаний. К примеру - вместо обзоров со скриншотиками однотипных и, будем честны, никому не нужных дистрибутивов - можно сделать уклон в Gentoo или отечественную гордость Calculate Linux, пояснив, что каждый, кто хочет в кратчайшие сроки понять суть Линукса - просто-таки обязан попробовать эти дистры. Я сам не гентушник, отнюдь. Но да, в своё время именно для этого её себе и ставил. А что касательно Calculate - ну да, гордость берёт за то, что наши такой вклад несут, да и сам дистр крайне дружелюбен. Потом можно рассмотреть LFS, серверные оси, создание портабельных дистров под свои нужды. Если нужен именно СЕО-хайп - то лучше бить в кастомизацию популярных дистрибутивов. Да-да, именно путём БолдженОС и Дениса Попова, но называя вещи своими именами - просто залезая вглубь дистрибутива, кастомизируя его, с целью популяризировать Линукс, заинтересовать и поднять уровень среднестатистического пользователя. Ну и всякие DE обозревать. Особенно не стандартные, к примеру https://www.enlightenment.org/ - которая развивается с 1996-го года и, как по мне - весьма футуристично обогнала все DE на несколько десятилетий. Опять же - я ей не пользуюсь, но считаю, что такое нужно знать и пробовать для себя.
Попробую заинтересовать авторов статей, да и всех желающих, у кого есть немного свободного времени и желание в кратчайшие сроки прокачать скиллы до неслабого уровня, заиметь кастомизированный, анонимный и безопасный (что крайне важно в наше время) дистрибутив:
Есть такая штука, как Liberte Linux. В своём роде - весьма уникальный и нужный портабельный дистр с мимимальными размерами и требованиями к железу. При этом анонимность, приватность и безопасность в целом - максимализирована. Автор его забросил, но я бы так не сказал. Читая его комменты на Опеннет - он прямо сказал, что свою задачу выполнил. И я с ним согласен. Этот Максим Краммерер создал уникальный в своём роде дистрибутив, который в два счёта компиллируется, масштабируется и допиливается под свои нужды. Это во многом превосходит легендарный LFS и в тоже время не требует таких знаний по порогу вхождения, как LFS, т.к. с Lieberte может разобраться каждый.
Надеюсь, хоть кого-то заинтересовал;)
Успехов всем и участникам проекта - в первую очередь.
С уважением.
База.
Вода вода вода
Зачем писать как работает json?!
And и or если в примере только and
must - and, should - or.
Хорошая статья. Длина - только плюс.
Тем, кому не нравятся - читайте про так как МС установить.
Можно ли cvs формат загрузить в еластик?
Спасибо за прекрасные примеры!
Хочется увидеть продолжение, желательно такое-же длинное, с большим количеством примеров.
Можно про анализаторы, можно про плагины, можно про более сложный поиск в elasticsearch-e.
В Интернете очень мало статьей по “Упругому поиску”. Как один из вариантов обучения – это читать unit-тесты автора elastica. Elatica – это php клиент Для elasticsearch https://github.com/ruflin/Elastica/tree/master/test
Спасибо! Материал действительно оказался очень полезным! В закладки.
Подскажите, если не зашло, как удалить elasticsearch с сервера? какой командой?
yum remove elasticsearch, а затем вручную удалите репозиторий /etc/yum.repos.d/elasticsearch.repo и удалите папку с индексами: /var/lib/elasticsearch
Большое спасибо. Уже месяц читаю ваш сайт, добавил в закладки, много полезного.
И сайт хороший и полезный и статья тоже. по ней и устанавливал, а критики покажите свой сайт и свои статьи, которые лучше этих. а если нет, то и не надо тут.
но я столкнулся с еще одной интересной задачей. стоит на сервере версия эластика 1.6, а хочется поставить хотя бы 6 серию, или 7ю. а у них совсем разный синтаксис и команды. пробовал просто механически на новой версии запустить. но посыпались ошибки. причем пемяю то на что жалуется, на то что само же и предлагает, а ошибки не прекращаются. долго не занимался, понял после очередного исправления, что тут без плана перехода не обойтись, а в инете все обрывочно и в основном тоже вопросы, а не ответы. если есть возможность и нужна тема для очередной статьи, прошу рассмотреть делать статью о переходе с версии 1 серии на относительно новую не менее 5й по Вашему выбору. пусть даже в основном переведенная, ибо лучшего я еще не нашел.
уточнение. содержимое индекса вообще не нужно сохранять. сайт так сконфигурирован, что через час даже не надо вспоминать что индекс был удален. а в основном все статьи как раз на сохранение индекса, а не сам перевод кода сайта, который у меня на пхп сделан.
Добрый день
Полезная статья, очень
А как удалить не один индекс, а несколько ? А место на диске освободится после удаления ?
А как настроить elasticsearch, чтобы квота на свободное место была не 90%, а скажем 95 ?
Борюсь с ошибкой high disk watermark 90 exceeded on